Optimal Execution via RL
The overarching goal of an optimal execution algorithm is to place limit orders in order to buy/sell a set number of units of an asset over a fixed time horizon so that the price paid/gained is optimal in relation to the transaction prices observed and the whole volume is executed.
Execution algorithms face a dilemma, if the algorithm places orders slowly and with low volumes, then the execution is exposed to the fluctuation of future market prices i.e. it is exposed to uncertainty, on the other hand, if orders are placed fast with high volume then this signals to the rest of the market that a big volume is expecting to be transacted, which leads to price change as the market reacts accordingly, this is known as “market impact”.
With the advent of modern Machine Learning, Reinforcement Learning has become a viable way to tackle the optimal execution problem algorithmically. Reinforcement Learning techniques aim to solve inter-temporal choice planning problems in which RL agents learn to maximise the rewards obtained from series of actions that affect the “state of the world” i.e. the environment the agents operates in. RL agents are not developed with a priori knowledge/assumptions of the nature of the problem, they are designed to be able to interact with their environment in order to learn patterns and choices that lead to positive rewards.
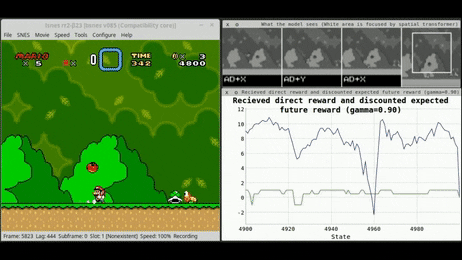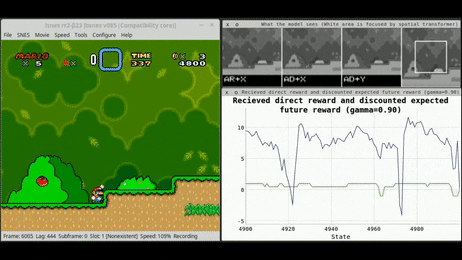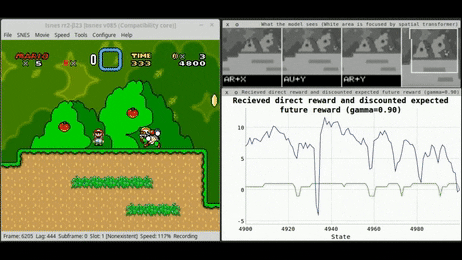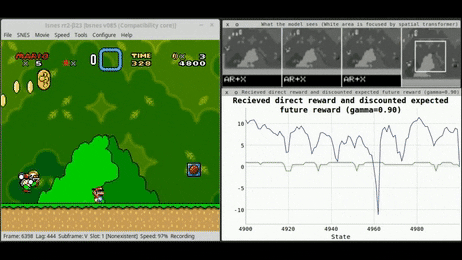
A small number of well-known algorithms dominate the commercial offering of execution services. Examples include:
- Algorithms that attempt to directly capture the VWAP (Volume Weighted Average Price) benchmark such as Percentage-Of-Volume.
- Algorithms that aim to participate in a given % of market volume.
- Time Weighted Average Price (TWAP) algorithms that submit child orders of the same volume at a constant rate.
- Algorithms that interact with the bid/ask spread.
All of these algorithms incorporate a relatively limited amount of market information in their decision-making process and decide order submissions based on relatively straightforward easily explainable rules.
In our usecase we explore all the challenges involved in the development of RL Algorithms that can incorporate aribitrary market data in their decision-making. Earlier works in the topic focus on the Neural Network (NN) Architectures used as agents and the RL optimization methods employed, as it is common in other areas of RL research. However, one crucial characteristic of RL applied in market applications is that the true environment is inaccessible and thus it is necessary to simulate its behaviour , be it via historical data or data generation approaches.
This challenge constitutes an additional level of choice compared to RL settings with access to their true environment. Different simulation setups differ not only by the NN agents and RL optimization methods they employ, but also by the type of market simulation they implement (that is, by the environment of their RL setup). The performance of a given agent + optimization method does not necessarily generalize to different simulation setups and the ability of a setup to replicate the behavior of a real market is in itself a major challenge.
In order to ease the implementation of different simulation setups, we have developed a modular framework for the application of Reinforcement Learning to the problem of Optimal Trade Execution. The framework is designed with flexibility in mind, in order to ease the implementation of different simulation setups. Rather than focusing on agents and optimization methods, we focus on the environment and break down the necessary requirements to simulate an Optimal Trade Execution under a Reinforcement Learning framework such as:
- Data pre-processing
- Construction of observations
- Action processing
- Child order execution
- Simulation of benchmarks
- Reward calculations

We give examples of each component, explore the difficulties their individual implementations & the interactions between them entail, and discuss the different phenomena that each component induces in the simulation, highlighting the divergences between the simulation and the behavior of a real market.
For more information regarding the usecase see our paper: link
See also the Project’s initial planned WorkFlow: link
And star our public Github repository: link
You can also visit the literature we went over while working on this Usecase here