5. Swiss-AL Pipeline#
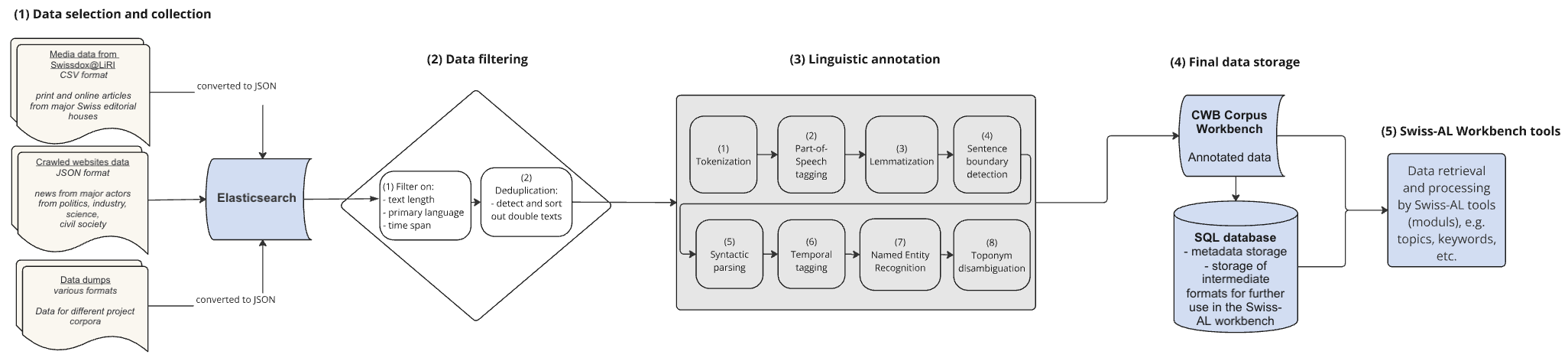
The Swiss-AL Pipeline is a step-by-step process for collecting, processing, and organizing text data. The pipeline starts by gathering texts from different sources like media databases, websites, and digital archives. Then, the data is carefully checked, filtered, and labeled with useful linguistic information. Finally, it is stored in special databases, making it easy to access and analyze. This section explains each stage of of the pipeline in more detail.
5.1. Data Selection and Collection#
The data for Swiss-AL corpora come from various sources:
Swiss Media Database: retrieved through Swissdox@LiRI.
Crawled Data: from a carefully selected set of websites from Swiss actors of public communication, such as government websites, political parties, etc. We use (Selenium) for browser automationwhenever it is needed (for websites that load data dynamically).
Data Dumps: Includes sources in other formats, like database dumps of specific projects.
All data, including metadata, are converted (if necessary) into JSON format and stored in Elasticsearch. Elasticsearch is a distributed, open-source search and analytics engine designed for fast and scalable full-text search. As all the other components, it is hosted on ZHAW servers.
5.2. Data Filtering#
5.2.1. Filter#
Documents in Elasticsearch are filtered based on the following criteria:
Word Count: Documents less than 100 words or more than 10’000 words are excluded from further processing. As a result, very short news snippets and long-form journalism may not be represented.
Language: Document languages are identified using the Compact Language Detector. This detector determines the primary language and annotates segments in other languages as foreign. Foreign language segments (e.g. quotes) are not removed from the text, but they are annotated as such (e.g. “FM” in the German tagset).
Date Filtering: Documents are filtered by specific dates to align with the defined timespan of the corpora. Texts for which no date can be detected are filtered out. For instance, in high-reach journalistic corpora, we consider texts published from 2010 onward.
5.2.2. Deduplication#
Deduplication removes duplicate or highly similar texts based on a predefined similarity threshold. Texts that exceed this threshold are filtered out to ensure that only unique content remains in the corpus. This process improves the accuracy of frequency analysis and helps avoid biases. As a threshold, we use a Jaccard overlap of 0.85 within the SpotSigs algorithm.
However, it means that identical or almost identical texts (i.e., reports from media agencies cited in various publications) will not reflect their full numerical presence in the media landscape.
5.3. Linguistic Annotation#
Linguistic annotation refers to the process of enriching text data with linguistic information. It involves adding structured labels or metadata that describe various aspects of language, such as word boundaries, part-of-speech categories, or named entities like people and locations. For all Swiss-AL corpora, linguistic annotation is done automatically by Natural Language Processing (NLP) tools. The annotation makes texts easier to query and analyze.
If you want to know the accuracy of a particular tool, please consult the publications related to that tool.
We do not perform error analysis ourselves, so please contact us if you notice systematic annotation errors (e.g., if verbs are consistently annotated as nouns, or if certain annotations are missing).
5.3.1. Tokenization#
The first step involves breaking down the text into smaller units called tokens. Tokens are the smallest meaningful units in a text that a computer can process. In natural language processing (NLP), tokenization is the process of breaking a text into these units, which can be words, punctuation marks, numbers and other character sequences.
For example, in the sentence: “The cat sat on the mat.” The tokens might be: [“The”, “cat”, “sat”, “on”, “the”, “mat”, “.”]
Although each tokenizer has its own language-specific rules, tokens can also be roughly defined as sequences of characters separated by whitespace or non-letter characters. For tokenization, we use TreeTagger.
5.3.2. Part-of-Speech Tagging#
This step identifies the word categories of the tokens, such as nouns, verbs, or determiners. Even punctuation is tagged (i.e., a period “.” could represent a sentence terminator or be part of an abbreviation). The tagger uses the context of surrounding words for accurate syntactic identification. For German, we use the STTS tagset. For French and Italian, we use the tagsets created by Achim Stein. For assigning Part-of-Speech tags automatically (i.e. tagging), we use TreeTagger. Next to pos tags, German texts have additional, rfpos tags, which store morphosyntactic information (see Search Modes) produced by RFTagger.
5.3.3. Lemmatization#
Following PoS tagging, each token is assigned it’s lemma (basic form).
For example:
-German denkst ‘(you) think’ and dachte ‘tougth’ are lemmatized as denken (‘to think’).
-French mangeais (‘was eating’) and mangé (‘eaten’) are lemmatized as manger (‘to eat’).
-Italian pensavi (‘you were thinking’) and pensato (‘thought’) are lemmatized as pensare (‘to think’).
The PoS tagging step and lemmatization help distinguish words that look the same but have different meanings depending on their role in a sentence.
German
Spiel (‘game’ – noun) and spiel (‘play’ – verb) are both written the same way but have different meanings.
If used in das Spiel (‘the game’), it remains a noun.
If used in Spiel mit mir (‘Play with me’), it is a verb.
PoS tagging helps determine the correct lemma: Spiel (noun) vs. spielen (verb).
French
marche can mean either:
La marche (‘the walk’ – noun) → lemma: marche
Il marche (‘he walks’ – verb) → lemma: marcher
Italian
corso can mean:
Un corso (‘a course’ – noun) → lemma: corso
Ho corso (‘I ran’ – verb) → lemma: correre
By combining lemmatization and PoS tagging, linguistic tools can correctly interpret words based on their context.
For lemmatization, we use TreeTagger.
5.3.4. Sentence Boundary Detection#
Boundaries between sentences are detected using punctuation marks like periods (.), exclamation marks (!), and question marks (?). This ensures correct sentence segmentation in further analysis.
5.3.5. Syntactic Parsing#
In this step, the grammatical structure of sentences is analyzed to identify syntactic roles such as subjects, objects, and modifiers. German and French texts are parsed with Mate Parser. For Italian we use the Stanford CoreNLP Parser.
5.3.6. Temporal Tagging#
This step identifies specific points in time, either through explicit dates (i.e., 2024) or relative expressions (i.e., today, last week), which are linked to the publication date of the text. For temporal tagging we use HeidelTime.
5.3.7. Entity Recognition#
Entities identifiable by proper names, i.e., people, locations, organizations, are tagged and classified into categories. This process uses the Stanford Named Entity Recognition software.
5.3.8. Toponym Disambiguation#
Geographic names (toponyms) undergo ambiguity resolution. This process distinguishes between locations with identical names,using contextual information to determine the correct location. For Toponym Disambiguation we use CLAVIN.
→ Go to Advanced Search to see which annotations you can query directly in the Platform and how.
5.4. Final Data Storage#
Processed and annotated corpora are stored in IMS Open Corpus Workbench (CWB), which contains open-source tools for managing and querying large text corpora with linguistic annotations. Storing data in the CWB format enables fast access to data that are retrieved for Swiss-AL tools Context of Words and Distribution of Words.
The CWB format is not suitable for certain Swiss-AL tools, such as Topics and Keywords. For these modules, we store their results in the SQL Database, from which they can be more easily retrieved. The SQL Database is used by other tools as well, in addition to CWB. It is also used for storing corpus metainformation, such as corpus types (media, organisational, etc.), corpus sources, and other information about the texts.
5.5. Tools in the Swiss-AL Platform#
Depending on users query, Swiss-AL Platform tools (see Tools) retrieve information from either CWB and/or from the SQL Database, process the data and visualise the results on the Swiss-AL Platform. For example, text snippets that can be accessed in Context of Words are retrieved from CWB, where full texts are stored. Topics, on the other hand, are retrieved from the SQL database, where word lists are stored.